git内部存储原理
cs61b的一个实验是mini-git,借此看看git内部是如何存储数据的。
Git对象
blob object
Git内部对象的存储是一个kv库。key为SHA-1的哈希值,value为具体文件。接下来我们通过一个小小的实验来看看。
首先需要初始化一个git仓库。
1 | |
接着我们可以用git hash-object向这个kv库中添加数据对象。 -w 选项会指示该命令不要只返回键,还要将该对象写入数据库中。 最后,--stdin 选项则指示该命令从标准输入读取内容;若不指定此选项,则须在命令尾部给出待存储文件的路径。
1 | |
接着我们可以用find .git/objects -type f查看具体有些什么对象了。
1 | |
接着你可以用git cat-file -p 通过key查看具体blob内容。
1 | |
现在我们已经大致明白这个kv库的工作模式。我们开始尝试对文件进行版本管理。首先我们先创建一个test.txt,并写入一定的内容。
1 | |
这里我们可以再试试git cat-file -p命令,
1 | |
接着我们创建版本2
1 | |
可以尝试用find .git/objects -type f命令查看一些有几个对象了。
1 | |
以上这些对象都只是一个内容的存储者,我们可以称之为blob object,其并没有保存比如文件名之类的信息。我们可以使用git cat-file -t查看blob类型。
1 | |
tree object
tree object的出现就是为了解决文件名的存储问题。具体我们来看看。
通常,Git 根据某一时刻暂存区所表示的状态创建并记录一个对应的树对象。 因此,为创建一个树对象,首先需要通过暂存一些文件来创建一个暂存区。
可以通过底层命令 git update-index 为一个单独文件——我们的 test.txt 文件的首个版本——创建一个暂存区。
--add:将指定的文件信息添加到暂存区中。--cacheinfo:手工指定文件的模式(权限)、SHA-1 哈希值和文件名。100644指这是一个普通文件。现在,可以通过1
2$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtgit write-tree命令将暂存区内容写入一个树对象。我们可以使用1
2
3
4$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtgit cat-file -t验证其为tree object。接着我们来创建一个新的树对象,它包括1
git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579test.txt文件的第二个版本,以及一个新的文件:再跑一跑上面的步骤创建tree object。1
2
3
4$ echo 'new file' > new.txt
$ git update-index --add --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add new.txt当然也支持将第一个tree object1添加到tree object21
2
3
4
5$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt现在你的tree object大概是这样:1
2
3
4
5
6
7$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt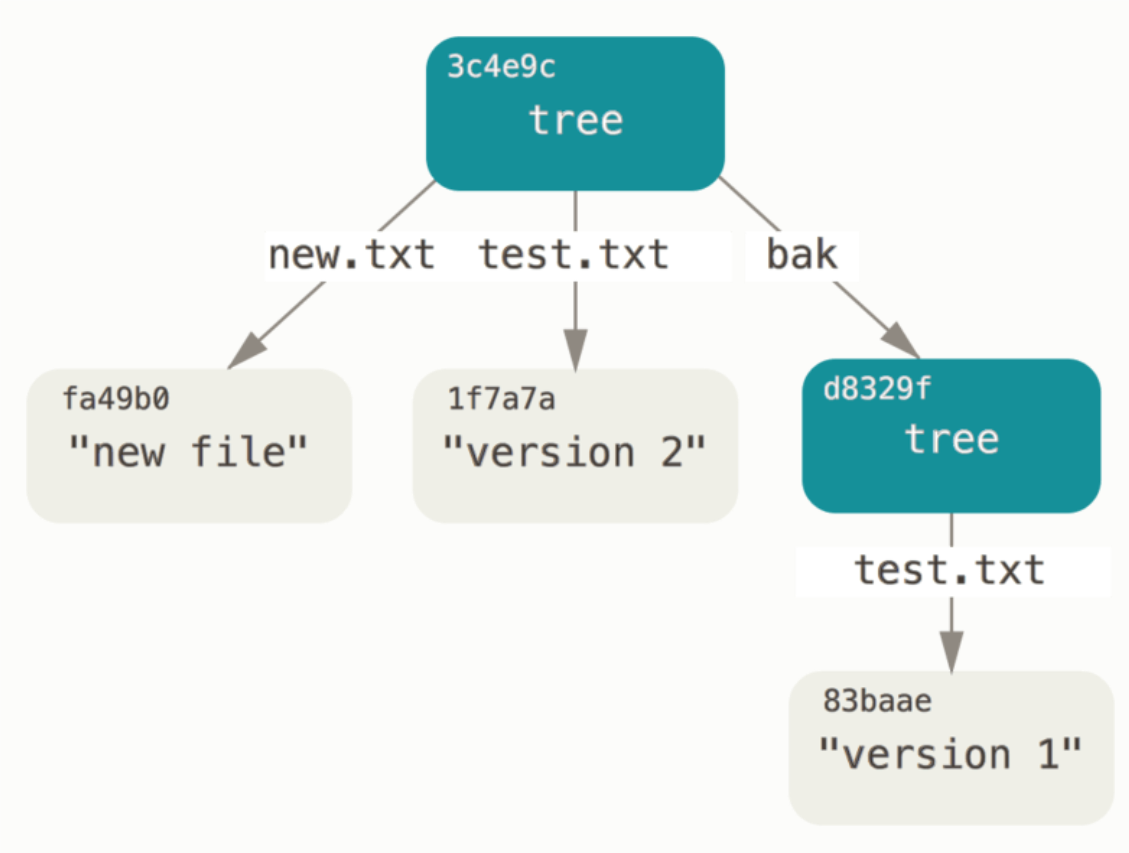
commit 对象
如果你做完了以上所有操作,那么现在就有了三个树对象,分别代表我们想要跟踪的不同项目快照。 然而问题依旧:若想重用这些快照,你必须记住所有三个 SHA-1 哈希值。 并且,你也完全不知道是谁保存了这些快照,在什么时刻保存的,以及为什么保存这些快照。 而以上这些,正是commit object能为你保存的基本信息。
可以通过调用 commit-tree 命令创建一个提交对象,为此需要指定一个树对象的 SHA-1 值,以及该提交的父提交对象(如果有的话)。 我们从之前创建的第一个树对象开始:
1 | |
提交对象的格式很简单:它先指定一个顶层树对象,代表当前项目快照; 然后是可能存在的父提交(前面描述的提交对象并不存在任何父提交); 之后是作者/提交者信息(依据你的 user.name 和 user.email 配置来设定,外加一个时间戳); 留空一行,最后是提交注释。
接着,我们将创建另两个提交对象,它们分别引用各自的上一个提交(作为其父提交对象):
1 | |
这三个提交对象分别指向之前创建的三个树对象快照中的一个。 现在,如果对最后一个提交的 SHA-1 值运行 git log 命令,会出乎意料的发现,你已有一个货真价实的、可由 git log 查看的 Git 提交历史了:
1 | |
现在内部的对象关系大概是这样: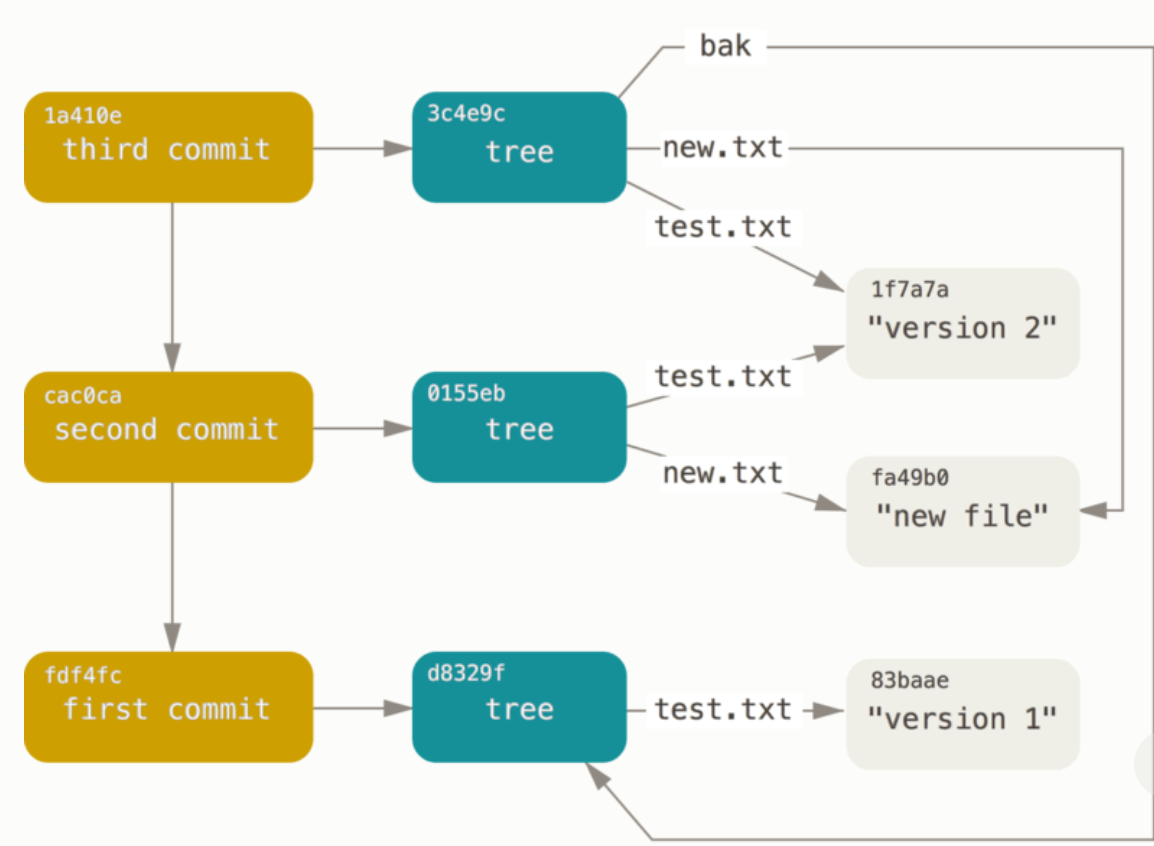
备忘录
test content -> d670460b4b4aece5915caf5c68d12f560a9fe3e4
test.txt -> version 1 -> 83baae61804e65cc73a7201a7252750c76066a30
test.txt -> version 2 -> 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
tree object 1-> test.txt version1 -> d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree object2 ->test.txt version2 new.txt -> 0155eb4229851634a0f03eb265b69f5a2d56f341
tree object3 -> tree1 + tree2 -> 3c4e9cd789d88d8d89c1073707c3585e41b0e614
commit1 -> tree1 -> 2f907b2fd7fef414713baabbd6db08cfcee8bdff
commit2 -> tree2 -> cf5d1d819f739c7e4a124c94996735b942bd2ea8
commit3 -> tree3 -> e3d828ca5b56c97911317033bf8243af31c15fc2