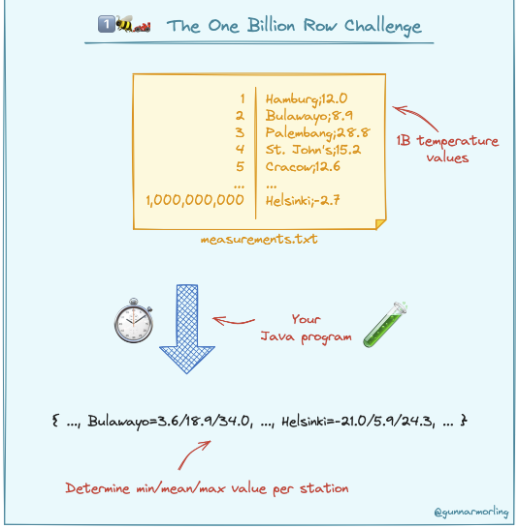
// 1.deal data startTime = time.Now() nowData := dealData(data)
// 2.sort by city ids := make([]string, len(nowData)) i := 0 for k, _ := range nowData { ids[i] = k i++ } sort.Strings(ids)
// 3. print sort by city fmt.Print("{") for i, id := range ids { if i > 0 { fmt.Print(",") } m := nowData[id] fmt.Printf("%s=%.1f/%.1f/%.1f", id, float64(m.min)/10.0, float64(m.sum)/10.0/float64(m.count), float64(m.max)/10.0) } fmt.Println("}")
funcdealData(data []byte)map[string]*Result { var temp int64 var city string start := 0 number := false tmp := &Result{} ans := make(map[string]*Result)
for i, v := range data { if v == '\n' { tmp = ans[city] tmp.min = min(temp, tmp.min) tmp.max = max(temp, tmp.max) tmp.count += 1 tmp.sum += temp
start = i + 1 temp = 0 number = false } elseif v == ';' { city = string(data[start:i]) if ans[city] == nil { ans[city] = &Result{ min: 1_000_000_000, max: 0, } } number = true } elseif number && v != '.' { temp = temp*10 + int64(data[i]-'0') } }
var wg sync.WaitGroup wg.Add(len(chunks)) results := make([]map[string]*Result, len(chunks)) start := 0 for i, chunk := range chunks { gofunc(data []byte, i int) { results[i] = processChunk(data) wg.Done() }(data[start:chunk], i) start = chunk } wg.Wait()
ans := make(map[string]*Result) for _, r := range results { for id, rm := range r { m := ans[id] if m == nil { ans[id] = rm } else { m.min = min(m.min, rm.min) m.max = max(m.max, rm.max) m.sum += rm.sum m.count += rm.count } } } return ans }
funcprocessChunk(data []byte)map[string]*Result { var temp int64 var city string start := 0 number := false tmp := &Result{} ans := make(map[string]*Result)
for i, v := range data { if v == '\n' { tmp = ans[city] tmp.min = min(temp, tmp.min) tmp.max = max(temp, tmp.max) tmp.count += 1 tmp.sum += temp
start = i + 1 temp = 0 number = false } elseif v == ';' { city = string(data[start:i]) if ans[city] == nil { ans[city] = &Result{ min: 1_000_000_000, max: 0, } } number = true } elseif number && v != '.' { temp = temp*10 + int64(data[i]-'0') } }
funcprocessChunk(data []byte)map[string]*Result { // byte -> string need optimization var temp int64 var city []byte start := 0 number := false tmp := &Result{} tmpAns := NewMyByteMap() var key uint16
for i, v := range data { if v == '\n' { tmp = tmpAns.FindByKey(key, city) tmp.min = min(temp, tmp.min) tmp.max = max(temp, tmp.max) tmp.count += 1 tmp.sum += temp
start = i + 1 temp = 0 number = false } elseif v == ';' { city = data[start:i] key = tmpAns.GetKey(city) if tmpAns.FindByKey(key, city) == nil { tmpAns.InsertByKey(key, city, &Result{ min: 1_000_000_000, max: 0, }) } number = true } elseif number && v != '.' { temp = temp*10 + int64(data[i]-'0') } }
ans := make(map[string]*Result, len(tmpAns.Value)) // tmpAns.Value -> initToByte for _, v := range tmpAns.Value { if v == nil { continue } for _, tv := range v { ans[string(tv.key)] = tv.value } } return ans }